
TL;DR:
For non-data practitioners: If you want a consistent AI model result in real-life, do study Matthews Correlation Coefficient as an additional evaluation metric.
For data practitioners: If you are dealing with an imbalanced dataset and wish to better evaluate your model, Matthews Correlation Coefficient might pique your interest 👍🏻
Hòla 👋
My name is Rex and I will try to keep this article as less technical as possible to communicate more effectively with readers without a programming or data science background.
What are we achieving?
The AI team in Revenue Monster Sdn Bhd has been working hard on a physical tampering detection problem on a set of sensitive documents. The main goal of this system is to identify if a document contains physical tampering or forgery traces (Adobe has introduced a way to identity digital tampering in an image, click here if you’re interested). In a way, we are building a physical fraud detection system on a set of images.
We introduced a two-stage deep convolutional neural network framework that can detect traces of physical tampering exhibit in a document and we managed to obtain a high accuracy score of 95% and we were happy until we received initial feedbacks from our client.
High fraud detection accuracy with low false alarm rate
One of the main challenges in building the aforementioned system, or any fraud detection system is procuring positive (fraud) samples. It is very hard to detect and obtain fraud samples across a data lake of legitimate samples. The fallout of this is a poor user experience for genuine users since the classifier will inadvertently flag some legitimate transactions.
We overcame this problem by introducing more training data over time, review our sampling approaches, and also investigate further into model penalization and evaluation… I will explain more of this later in the future.

In the know
Now that our models are built, it’s time to evaluate their performances.
We deployed our best model for client testing and the feedback we acquired was subpar.
The unseen testing examples carry new forgery variations. They introduced a several refreshing form of physical tamperment and our model was misclassifying it, albeit the stellar 95% accuracy.
That’s when we know we had to review our evaluation methods, be in the know.
The usual evaluation approaches
Accuracy, recall, precision, F-Measure, TPR, FPR, Kappa…
Let’s take a slight detour and recapitulate how practitioners from different domains evaluate their models
1. Medical sciences— Receiver Operating Characteristics (ROC), TPR, FPR
2. Behavioral sciences— Specificity/Sensitivity, Cohen Kappa
3. Computer sciences— Accuracy, precision, recall, F1, TPR, FPR
Scalar metrics are ubiquitous in machine learning domain and it is most familiar to most data scientists. However, they are biased and should not be used without a clear understanding of the biases, and corresponding identification of chance or base case level of the statistics.

In particular, let’s consider accuracy and F1-score as a metric with the Cat vs Dog Classification problem. F1-score or F-measure is the harmonic mean of the precision and recall.
-
Accuracy can be used when the class distribution is similar while F1-score is a better metric when there are imbalanced classes as in our system.
-
Accuracy is used when the True Positives and True negatives are more important while F1-score is used when the False Negatives and False Positives are crucial
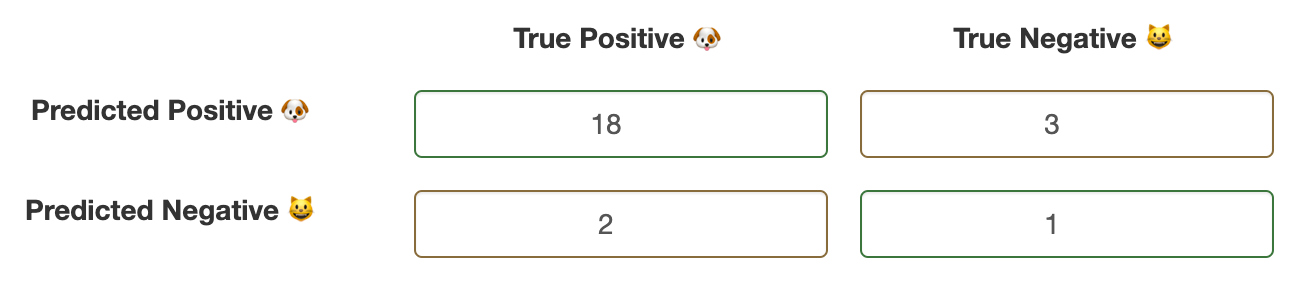
There are 24 samples in the above confusion matrix and it is easy to tell that the dataset is imbalanced, there are only 20 dogs and 4 cats pictures. If you compute, here’s the result you will get
-
Accuracy — 79%
-
Precision — 86%
-
Recall — 90%
-
F1-Score — 88%
Incredible! That’s a rather high 88% F1-score and we just got ourselves a fantastic classifier! Are we ready to deploy the model in a production environment? What if we flip the confusion matrix, would the F1-score persist?
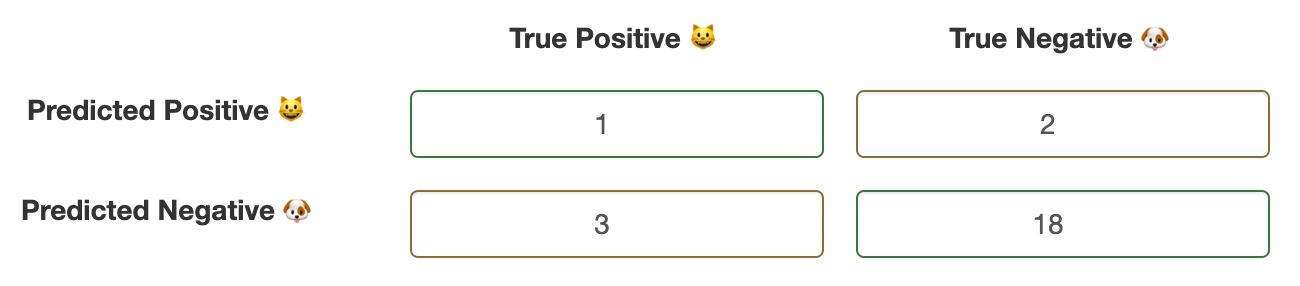
Sure enough, the F1-score plummets to 29% and our classifier is awfully bad at classifying cats. If you noticed, our accuracy hasn’t changed at 79% but how is it a reasonable measure when you think about it? Will you still get similar accuracy when testing in a production environment?
Here’s the fix: Matthews Correlation Coefficient
From the above examples, I hope it is now clear that the usual scalar metrics are not always suitable when dealing with imbalanced dataset scenarios, such as fraud detection. Let me introduce a fix: Matthews Correlation Coefficient (MCC), or *phi-coefficient *(φ).
Surprisingly, MCC is hardly talked about in any data science materials and most graduate studies. Our team learned about it the hard way and we hope this article can be beneficial to anyone in need.
In short, MCC is used to measure the quality of a binary or multi-classifier even if the classes are of very different sizes. It returns a value between -1 and 1 where
-
-1 — Total disagreement between prediction and observation
-
0 — No better than random prediction
-
1 — Perfect prediction
Here’s the formula for anyone who is interested:
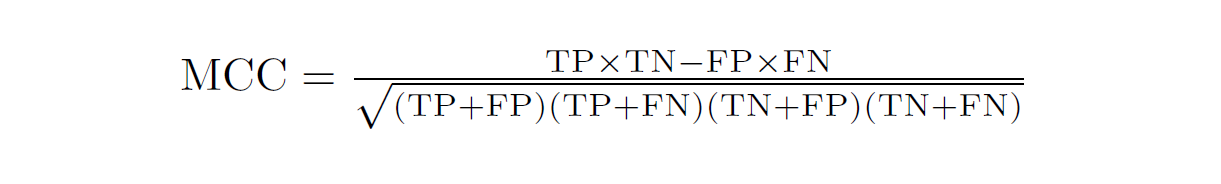
Coming back to the Cat vs Dog classification problem above, we are able to obtain an MCC score of 0.169. Hence, we can say that the classifier is no better than random and the classes are weakly correlated, albeit it is able to achieve a high accuracy score of 79%.
Unlike F1-score who ignores the count of True Negatives (TN), MCC takes into account all 4 values in the confusion matrix and thus all classes are treated as equal. If you flip the confusion matrix, you will still get the same result.
Implementation
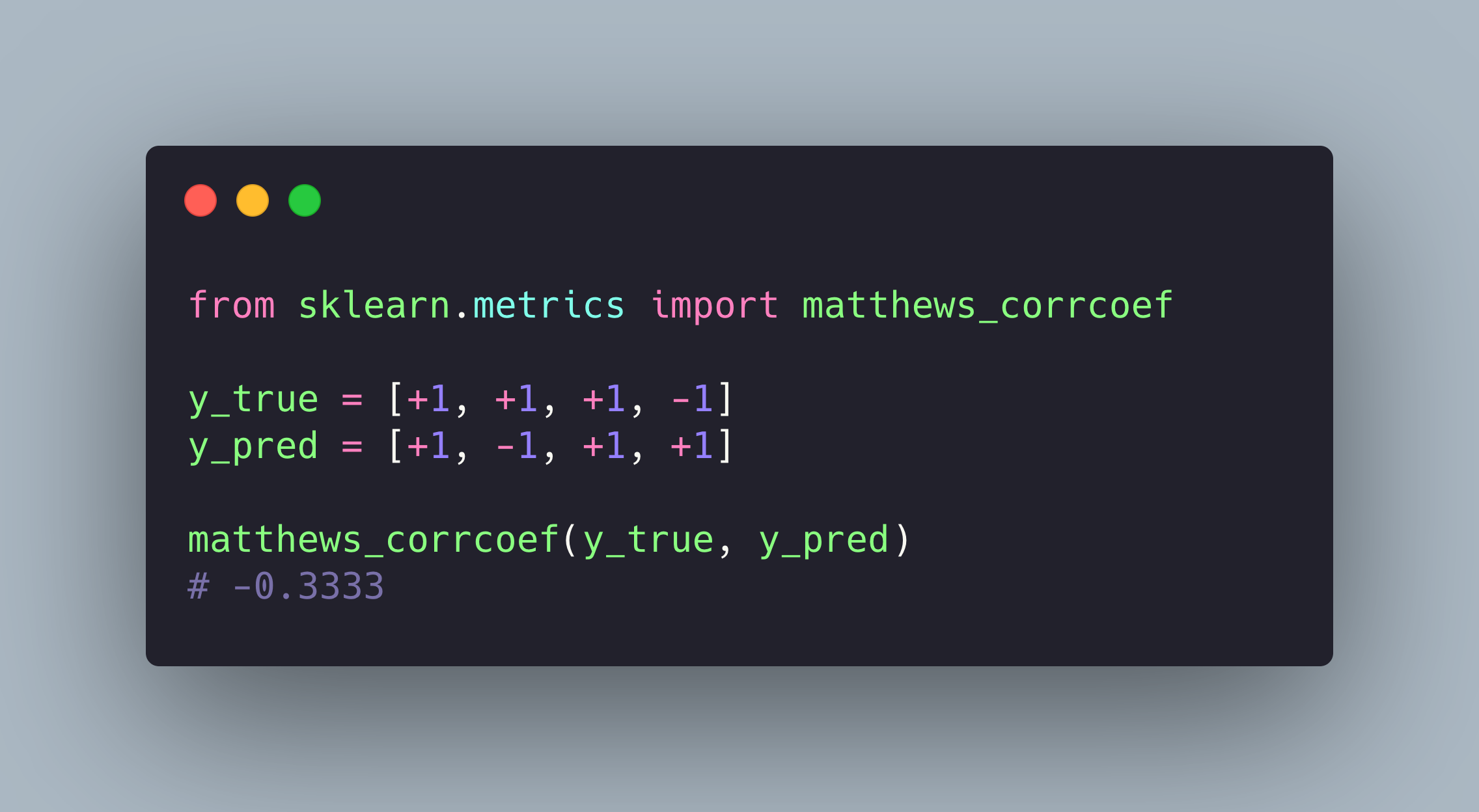
Enough talk, let’s code! Fortunately, MCC is already implemented in scikit-learn for both binary and multi-class classification problems.
Finale
Our team was able to rectify the issue thanks to MCC for helping us better evaluate our trained model. We were able to quickly modify some of the model parameters and finetune it with some other hacks, which hopefully I will write about in another article.
No one metric is better than another, we should all do our due diligence and study the underlying distribution of our data and tackle the problem accordingly!
Allow me some shameless plug 🗣
We are expanding our team, especially under Tech at Revenue Monster Sdn Bhd. We are hiring developers who speak frontend, backend, DevOps, and machine learning. Do reach out to my HR personnel via hr@revenuemonster.my if you’re interested to explore the FinTech world!